
The Rise of AI Agents: How NVIDIA, Meta, and OpenAI Are Reshaping the 2025 Workforce

The Rise of AI Agents: How NVIDIA, Meta, and OpenAI Are Reshaping the 2025 Workforce
(And What It Means for You)
Imagine a world where your coworker isn’t human—but a hyper-efficient AI agent that schedules meetings, predicts supply chain hiccups, and even cracks jokes during coffee breaks. This isn’t sci-fi; it’s 2025. Companies like NVIDIA, Meta, and OpenAI are racing to deploy AI agents that promise to revolutionize industries. But with great power comes great debate: Will these agents uplift workers or replace them? Let’s unpack the hype, the hope, and the hard truths.
Meet the Players: NVIDIA, Meta, and OpenAI
1. NVIDIA: The Brains Behind the Brawn
NVIDIA isn’t just about gaming GPUs anymore. Their AI agents, built on quantum-AI hybrids and advanced computing frameworks, are designed to optimize everything from drug discovery to urban planning. Think of them as the Swiss Army knives of enterprise AI, streamlining supply chains and powering real-time decision-making.
2. Meta: Social AI with a Human Touch
Meta’s agents focus on social integration—think AI assistants that mimic human empathy in customer service or mental health support. Their Llama models are evolving to handle nuanced conversations, though critics argue Meta’s hardware limitations might slow progress toward artificial general intelligence (AGI).
3. OpenAI: The AGI Trailblazers
Sam Altman’s OpenAI is betting big on autonomous AI agents entering the workforce by 2025. Their “Strawberry” model uses multi-step reasoning to solve complex tasks, like drafting code or diagnosing medical conditions. Altman claims these agents could boost company output by 30%—but warns of ethical pitfalls.
The Good, the Bad, and the Automated
Let’s break down the potential impacts of AI agents with a quick comparison:
| Aspect | Positive Impact | Negative Impact |
|---|---|---|
| Productivity | Automate 40% of repetitive tasks (e.g., data entry) | Risk of over-reliance on AI for critical decisions |
| Job Creation | 97M new roles in AI oversight and ethics | 300M jobs at risk in finance and retail |
| Healthcare | 90% of hospitals use AI for faster diagnostics (NVIDIA's vision) | Privacy concerns over patient data usage |
| Creativity | Generative AI aids designers and marketers | Potential homogenization of creative outputs |
The Bright Side: Why AI Agents Could Be a Win
- Supercharged Efficiency
AI agents excel at tasks humans find tedious. For example, NVIDIA’s AI orchestrators can optimize factory workflows in real time, cutting downtime by 40%. Meanwhile, OpenAI’s agents automate 89% of clinical documentation in healthcare, freeing doctors to focus on patients. - Democratizing Expertise
Small businesses can now access AI tools once reserved for tech giants. Meta’s AI assistants help startups automate customer service, while OpenAI’s GPT-4 enables solo entrepreneurs to draft legal contracts in seconds. - Solving Global Challenges
From climate modeling to pandemic prediction, AI agents analyze data at unprecedented scales. NVIDIA’s quantum-AI systems are accelerating carbon capture research by simulating molecular interactions in minutes.
The Flip Side: Risks We Can’t Ignore
- Job Polarization
While AI creates high-skilled roles, low- and mid-level jobs face displacement. Wall Street could lose 200,000 back-office jobs by 2025, and customer service roles are increasingly automated. - Ethical Quandaries
Bias in training data could skew hiring or lending decisions. A healthcare AI might misdiagnose marginalized groups if trained on non-diverse datasets. OpenAI’s Altman stresses the need for “explainable AI” to ensure transparency. - The AGI Uncertainty
What happens when AI outsmarts us? Meta’s Yan Lecun doubts AGI is near due to hardware limitations, but OpenAI’s 87.5% score on human-like reasoning benchmarks hints otherwise.
The Verdict: Collaboration Over Replacement
The future isn’t humans vs. machines—it’s humans with machines. For instance, Salesforce’s Einstein GPT doesn’t replace sales teams; it handles grunt work so they can strategize. Similarly, NVIDIA’s AI factories need engineers to oversee ethical AI deployment.
Key Takeaways for 2025:
- Upskill or Fall Behind: Learning to work alongside AI will be non-negotiable.
- Demand Transparency: Support regulations like the EU’s AI Act to curb misuse.
- Embrace Hybrid Workflows: Use AI for heavy lifting, but keep humans in the loop for creativity and judgment.
Final Thoughts
AI agents from NVIDIA, Meta, and OpenAI are neither saviors nor villains—they’re tools. Their impact depends on how we wield them. Will 2025 be a dystopia of job losses? Unlikely. But it will be a year of transition, where adaptability and ethical foresight determine who thrives.

Explore Our Latest Insights
Stay updated with our recent blog posts.
A new DataForSEO study of 100,000 ChatGPT prompts found that 47% of them trigger fan-out queries: hidden searches ChatGPT runs against the web before it answers. If your content does not match those hidden queries, you do not get cited. Here is how to find them and write content that does.
Why is there a "search you will never see" deciding if ChatGPT recommends you?
Because ChatGPT does not just take your question and go fetch an answer. It rewrites your question into multiple secondary questions, runs those against the web, then synthesizes the response. Those rewritten questions are called fan-out queries, and a DataForSEO study of 100,000 ChatGPT prompts found 47% of prompts trigger them.
Translation: the most important search query about your business is one no human ever typed. If your page does not answer that hidden query, ChatGPT skips you, even if you rank for the obvious keyword.
What are fan-out queries, exactly?
Fan-out queries are the secondary questions ChatGPT generates from your original prompt and runs against the web before answering you. They are the AI's way of saying "your query is not specific enough, let me search smarter."
Say a user types "best Italian restaurants in Chicago". ChatGPT might fan that out into:
- best Italian restaurants in Chicago reviews
- top Italian restaurant Chicago price
- popular Italian restaurants Chicago menu
Each of those is a real search query running silently behind the scenes. The pages that match those fan-outs are the pages ChatGPT cites and recommends. This is the mechanic behind every modern AI search engine, and it is the core of generative engine optimization.
Why does matching fan-out queries equal citations?
Because citations are awarded to pages that answer the AI's hidden questions, not the user's original one. ChatGPT, Perplexity, and Google's AI Overviews all rely on fan-out style retrieval. Match the fan-out, get the citation. Miss it, get ignored.
This is why a page can rank #1 in classic Google and still never appear in ChatGPT search. The traditional "head term" mindset does not survive in AI search. You have to think in clusters of sub-questions, which is exactly what the capsule content method was built for.
Community win: William Moon, a financial advisor in Arizona, took his CTR from 0.3% to 2.3% by rewriting his pages to answer fan-out style sub-questions, then closed a $165,000 deal off one AI-driven lead.
How do you find the fan-out queries running for your niche?
You need a fan-out dataset. The fastest way is a free tool called DataWise, which pulls fan-out queries from DataForSEO's index and gives you 5 free uses on signup.
The flow inside DataWise:
- Sign up free, land on the dashboard (your Google Search Console connection is optional).
- Go to Keyword Research and pick the Fan-Out Queries tab.
- Drop in your seed keyword, for example "local SEO", and hit Explore.
- DataWise returns the fan-out queries triggered for that seed, plus AI search volume and trends.
- Filter to only fan-out queries (you can skip "people also ask" and FAQs, which are different beasts).
- Export the ones that make sense for you to a CSV. That is your content plan.
Heads up: as of recording, fan-out data is US-English only. The dataset is brand new, so expect international expansion soon.
If you are technical, you can also wire DataForSEO directly into Claude Code and run fan-out research from your terminal. I walk through that setup in this video.
Which fan-out queries should you actually answer?
Pick the ones that match your service, your audience, and your buyer intent. Not every fan-out is worth answering, and AI search volume is not the only signal. If a fan-out query makes sense for your business and the question is clearly being asked by ChatGPT, that is enough reason to write the page.
Quick triage rules:
- Definitions: "what is X and how does it work" usually deserves a pillar post.
- Verticals: "X for lawyers / dentists / agencies" become dedicated niche playbooks.
- Comparisons: "X vs Y" or "is X worth it" map to comparison posts that AI loves to cite.
- Process: "how to rank in Map Pack" become tactical how-to articles.
You do not need to answer all 99 fan-outs DataWise returns. Pick the 8 to 12 that fit your offer and start there.
How do you write content that actually gets cited?
You answer the fan-out query directly, in the first sentence of the section, then expand. AI engines are looking for self-contained, extractable answers, not 1,500 words of warm-up before you say anything useful.
The repeatable structure that works in 2026:
- TL;DR or summary box at the top, 40 to 60 words, covering the whole article.
- Every H2 phrased as a question that maps to a fan-out query.
- Direct answer in the first 1 to 2 sentences of every section, then context.
- Schema markup (Article, FAQ, HowTo) so engines can parse it cleanly.
- Linked sources for every stat claim, because AI engines weight cited content higher.
This is the capsule content method in one paragraph. It is also exactly how this post is structured. If you want the full writing checklist, grab the free blog post optimization checklist here.
Frequently Asked Questions
What is a fan-out query in ChatGPT?
A fan-out query is a secondary question ChatGPT generates from your original prompt and silently runs against the web before answering. It is how the model gathers enough source material to give a confident response. The DataForSEO 100,000-prompt study found 47% of ChatGPT prompts trigger fan-outs.
How is a fan-out query different from "people also ask"?
People also ask is a Google SERP feature populated from real human searches. Fan-out queries are AI-generated rewrites that no human ever typed, used internally by ChatGPT and other LLMs to retrieve sources. Some overlap exists, but fan-outs are uniquely a generative engine optimization (GEO) signal.
Do fan-out queries work outside the United States?
Not yet. As of April 2026, the DataForSEO fan-out dataset only covers US-English queries. International coverage is expected to roll out as the dataset matures.
Can I find fan-out queries for free?
Yes. DataWise gives you 5 free fan-out lookups when you sign up, no credit card. After that you can either upgrade or join AI Ranking School for unlimited access.
Will ChatGPT cite my page if I just stuff fan-out keywords in?
No, and this is where most people screw it up. You have to genuinely answer each fan-out query in a self-contained section with a direct opening answer, supporting context, and ideally a linked source. Keyword stuffing reads as spam to LLMs the same way it does to Google.
Want unlimited fan-out research and the playbook?
DataWise is free to try with 5 lookups. If you want unlimited fan-out queries, the full content writing system, weekly tutorials, and a community of operators implementing this every week, join AI Ranking School. That is where members like William, Tim Armstrong, and Steven (800+ pages, 105 appointments/month) are running this play.
If you want to dig deeper before joining:

Fan-Out Queries: The Hidden ChatGPT Searches That Decide If You Get Cited
Most AI website videos ignore what happens after day one. This walkthrough combines Google Stitch, Claude Code, and Nano Banana Pro inside WordPress Studio to ship a local service business site (5 to 15 pages) that is SEO-ready, handoff-friendly, and built to evolve. WordPress still powers over 40% of the top 10 million sites, so this workflow is still incredibly valuable in 2026.
Why Does WordPress Still Win in 2026?
Because the best website is not the one that looks incredible on launch day, it is the one that keeps on working for months and years into the future. WordPress currently powers over 40% of the top 10 million websites on the internet, which means your client (or the next agency they hire) already knows how to edit it.
Most AI website videos skip the part where the site needs to evolve. You see a slick homepage, a drum roll, and then nothing about plugins, forms, schema, or what happens when the owner wants a new service page next Tuesday. WordPress is boring in exactly the right way for local service clients.
The problem was never WordPress. Almost nobody has been building WordPress sites with the modern AI stack. Let's fix that.
What Tools Do You Need for This Build?
You need three things, and two of them are free. The stack is WordPress Studio (local dev), Google Stitch (front-end design), and Claude Code with Nano Banana Pro for building and generating on-brand WebP images.
The short list:
- WordPress Studio: a free local WordPress environment by WordPress. Download it for Mac or Windows, or install it via CLI. Studio spins up a fully functional WordPress site on your machine with zero server setup.
- Google Stitch: a free (at time of writing) front-end design tool from Google. Great at homepages, services pages, and mobile app screens. We use it only for the style guide and layout reference.
- Claude Code inside Studio: Studio ships with a Claude MD file, an agents file, and pre-built skills for the Studio CLI. This is the piece that makes Claude Code the right tool for building websites in 2026.
- Nano Banana Pro API key: grab this from Google AI Studio so Claude Code can generate images directly inside the project.
One caveat: this workflow is optimized for local service businesses that need 5 to 15 pages. If you are building an e-commerce store or anything more dynamic, stick with WordPress and add a builder like Kadence or Elementor.
How Do You Design the Homepage in Google Stitch?
Start with a brand brief, not a blank canvas. Ask Claude (or any LLM) to generate a fake business doc with the name, tagline, positioning, NAP (name, address, phone), service areas, services, and credentials. Download it as a TXT file.
Then open Google Stitch, switch to the web workspace, and select Thinking with 3.1 Pro for more processing power. Upload the TXT file and prompt something like: "Create a homepage design for the business in the attached TXT file. Make it modern, with one cool and quirky callout color for CTAs."
Stitch will generate a homepage. If you want changes, ask for them. Stitch never overwrites previous versions, it creates a new one each time, so you can always walk back to the version you liked.
What you actually want from Stitch: the style guide and color palette. The layout is a nice bonus, but the real value is the consistent look and feel that you will feed into Claude Code in the next step. Right-click the design you like, download it, and keep it close.
How Do You Set Up WordPress Studio Locally?
Open Studio by WordPress, click Add a site, and name it after your client (we used "Copper State Electric" for a fake Arizona electrician). Studio creates a local folder with the full WordPress install.
Go to Settings and scroll to the bottom. You will see AI Skills and Agent Instructions panels. This is where you install the Studio CLI, which gives Claude Code the ability to build pages, inject plugins, and control form plugins like WP Forms. Restart Studio after install if needed.
Open the local folder in VS Code (or your editor of choice). You will see:
- A
Claude.mdfile - An
agentsfolder - A
skillsfolder loaded with MD files for the Studio CLI
That is the unlock. Studio is shipping pre-built Claude skills for WordPress, which is why the AI build quality in this setup is meaningfully higher than prompting a blank WordPress install.
Community win: Steven, an AI Ranking member, used a similar local-first, SEO-ready workflow to ship 800+ location pages that indexed in under an hour each. Result: 105 booked appointments from organic traffic in a single month.
How Do You Plan the Build with Claude Code + Ultra Think?
Before you let Claude write a single line, switch it to Plan Mode and enable Ultra Think (you will see the prompt turn rainbow). Plan mode forces Claude to outline the full build first so you can catch mistakes before any code ships.
Drop in the business TXT file and write a prompt along the lines of:
"Look through the TXT file. That is all the information for the website we are building in this project. Follow the best practices in the docs. First, think about the site structure. Once you are ready, we can build. Make sure everything is SEO optimized and follows best practices."
Claude will read the skills, propose a plan (plugins like Rank Math and WPForms Lite, page structure, schema, critical files, build sequence), and wait for approval. This is the same discipline we teach inside the AI Ranking community: plan first, verify, then build.
Approve the plan, let Claude bypass permissions, and walk away for 20 to 30 minutes.
What Should the First Build Actually Include?
A functional, SEO-first skeleton with schema, service pages, a blog, and a working lead form. The point is not perfection on run one, it is a serviceable v1 that you can iterate on.
What Claude Code shipped on the first pass:
- Homepage with hero, services, reviews, FAQ, and CTA
- Individual service pages (rewiring, EV installs, panel upgrades)
- Service area pages (Scottsdale, Mesa, Paradise Valley)
- Correct schema: FAQ schema and Electrician (LocalBusiness) schema
- Clean H1, H2, and meta structure
- Blog set up with a working "Hello World" test post
- WPForms install for lead capture
- Rank Math for on-page SEO
Pop open the site at localhost and check it with the SEOWallet Chrome extension. You should see valid schema, proper heading hierarchy, and meta descriptions everywhere. If anything looks off (a CTA button that is invisible on dark backgrounds, a weirdly centered container), screenshot it and send it back to Claude with fix instructions.
How Do You Generate On-Brand Images with Nano Banana Pro?
Tell Claude Code to generate in WebP format, not PNG. Always. WebP is Google's image format for faster page loads, and Nano Banana defaults to PNG unless you tell it otherwise.
Before generating anything, ask Claude to write a style guide for images first: camera model, focal length, lighting, color treatment. Pin that guide somewhere in the project so every image Claude generates matches. Consistency is the difference between a site that looks designed and a site that looks AI-generated.
Prompt example:
"Create a style guide for all images on this site. Include camera, focal length, lighting, and color treatment. Then generate the hero and service page images in WebP using that guide."
This one rule (WebP + a locked style guide) dramatically improves how coherent the final site feels. Image-heavy pages are also a major factor in AI search citations, because models often ingest alt text and surrounding context.
What SEO Fundamentals Must Be Non-Negotiable?
Each services page and area page needs to be at least 50% unique content compared to the others. This applies to written copy, images, image descriptions, schema, titles, and meta descriptions.
This matters because Google (and LLM-based search) will otherwise collapse near-duplicate pages into a single result. We covered this pattern in depth in AI website builders miss SEO fundamentals, and it is the number one reason programmatic service sites flop.
Checklist before you hand off:
- Rank Math SEO installed, every page has a unique title and meta description
- WPForms Lite installed with a tested submission path
- Every service page has unique H1, H2, and body copy
- Every area page has location-specific context (not just a swapped city name)
- Schema validates:
LocalBusinesson the homepage,Serviceon service pages,FAQPageon the FAQ - Images in WebP with descriptive alt text
- Internal links between services, areas, and blog posts
If any of those are missing, loop back to Claude with a screenshot and ask for a fix. That is the whole job.
Why Hand Off on WordPress Instead of a Modern Builder?
Because your client's next agency, VA, or marketing hire almost certainly knows WordPress. Handoff is the real test of a good build.
Webflow is my personal favorite for the sites I run, but clients inherit websites and those inheritors tend to panic when they open something they have never seen. A WordPress dashboard with Rank Math, WPForms, and a clean block editor is something they can actually keep up to date.
Community win: Tim Armstrong, another AI Ranking member, had a client land a mortgage lead directly from a ChatGPT recommendation where the AI called the client "the best option in America." That only happens when the site is technically sound and editable over time, not just pretty on launch day.
Frequently Asked Questions
Is WordPress still worth using in 2026?
Yes, for local service businesses and content-driven sites that need long-term editability. WordPress still powers over 40% of the top 10 million sites, and the AI tooling (WordPress Studio + Claude Code skills) has caught up fast.
Do I need coding skills to use WordPress Studio with Claude Code?
No. Studio ships with pre-built skills and an agent config. You direct Claude in plain English. Basic familiarity with the WordPress admin helps, but the build itself is prompt-driven.
Is Google Stitch required?
No, but it saves hours of back-and-forth on design. Stitch gives you a locked style guide and layout reference before Claude starts building, which reduces rework by a big margin.
What about AI Overviews and SearchGPT citations?
The same SEO fundamentals apply (clean schema, unique content, source links, real author bios). For the full playbook, read How to do SEO for SearchGPT and our AI content writing checklist.
How long does the full build take?
Roughly 45 to 90 minutes of active work, plus 20 to 30 minutes of unattended build time while Claude works through the plan. Image generation adds another 15 to 20 minutes.
Ready to Rank Whatever You Build?
Whether your client's site lives on WordPress, Webflow, Astro, or something more exotic, ranking it is a separate skill.
Inside the AI Ranking community you get the full workflow for getting local service sites cited in ChatGPT, Google AI Overviews, Perplexity, and traditional search. You can try it risk-free for 7 days, and members now get access to the in-house SEO tool for keyword research, competitor analysis, AI visibility tracking, and backlink audits, all included with membership.
If you want the free primer first, start with How to Get Found in AI Search.
Resources

How to Build a WordPress Website in 2026 with Claude Code, Google Stitch, and Nano Banana Pro
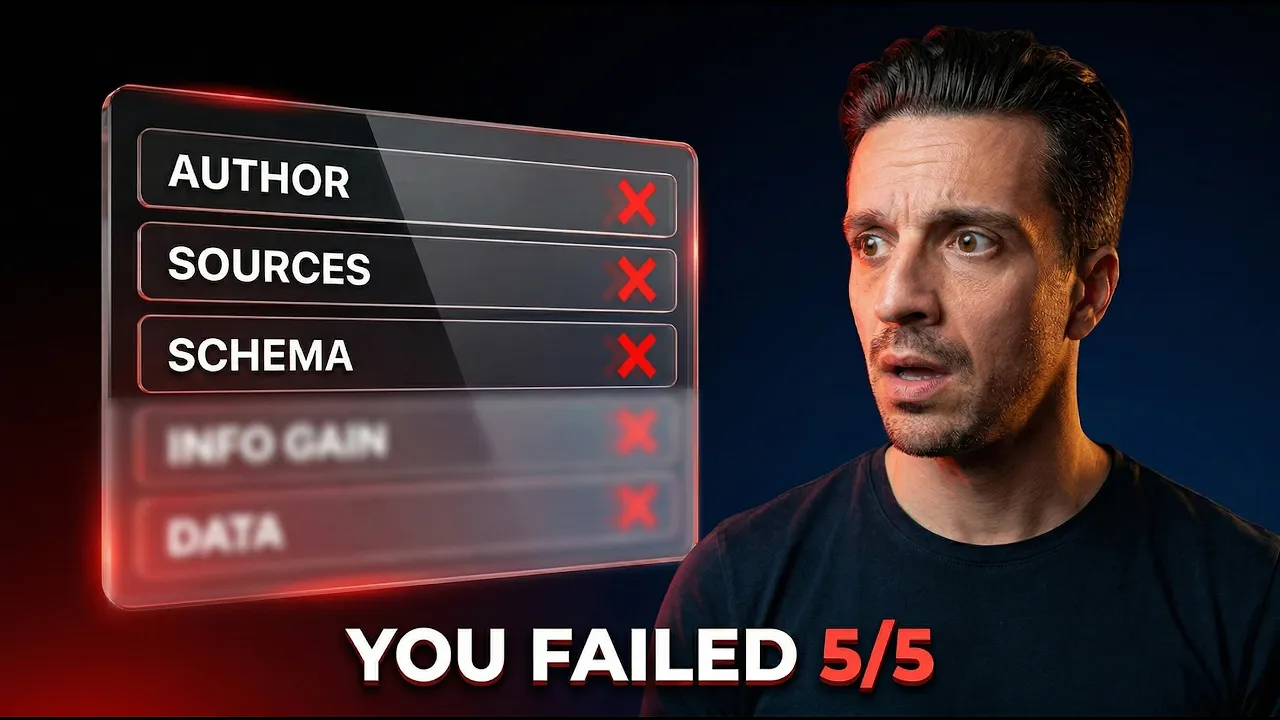
Google's March 2026 core update just finished rolling out, and older blog posts without proper trust signals are getting crushed. The five things Google now rewards: author bios, source links, information gain, schema markup, and original data. Fix these on your existing content before Google drops it entirely.
Why Is Google's March 2026 Core Update Different?
Because this one is quietly reshaping how content ranks in both traditional search and AI search engines. Google finished rolling out the March 2026 core update about five days ago, and the fallout is already visible.
Sites are bleeding traffic, and Google (as usual) won't tell you exactly why. But if you look at the data from SISTRIX's volatility analysis and Search Engine Roundtable's coverage, there's a clear pattern. Blog posts that lack specific trust signals are getting demoted or dropped entirely.
This matters more now than ever. Over 50% of Google searches now trigger AI Overviews, and if your content isn't cited in those AI responses, you're looking at a 61% CTR drop. The good news: there are exactly five trust signals you can add to fix this. Let's break them down.
What Are the 5 Trust Signals Google Now Rewards?
Google is rewarding content that proves its credibility through verifiable signals. The five trust signals are: author bios, source links, information gain, schema markup, and original data.
Think of these as the checklist Google's quality raters (and the large language models powering AI search engines) use to decide whether your content is worth surfacing. If your old blog posts are missing even two or three of these, you're handing rankings to competitors who have them.
The encouraging part is that most of these are straightforward to implement. Some take five minutes. Others require a bit more thought. Let's go through each one.
Does Every Blog Post Really Need an Author Bio?
Yes. Every single one. An author bio is the easiest trust signal to add, and it's the first thing Google's E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) framework looks for.
Here's the problem: most CMS platforms default to "Written by Admin" or nothing at all. That tells Google (and your readers) absolutely nothing about why this person is qualified to write on the topic.
What a good author bio includes:
- The author's full name and a short summary of their expertise
- A link to their full bio page on your site
- Links to their LinkedIn profile and other social media
- A list of other articles they've written on your site
This creates a trail of verifiable trust. Google can follow those links, confirm the person exists, and confirm they actually have experience in the field. Your readers can do the same.
The implementation is simple. Practically every CMS (WordPress, Webflow, Astro, whatever you're using) has an option to create author profiles and assign them to blog posts. If yours doesn't, add a formatted author box at the bottom of each post manually.
Community win: William Moon, a financial advisor in Arizona and AI Ranking member, added proper author bios (linking to his credentials and LinkedIn) across his blog. His CTR jumped from 0.3% to 2.3%, and he closed a $165,000 deal directly from organic traffic. Trust signals compound.
Why Are Source Links So Important After This Update?
Because Google rewards transparency. Every factual claim you make should link to a high-quality source backing it up. Even if you're the subject matter expert and you know the answer from years of experience, Google doesn't care. They want receipts.
Here's a simple example. If you're writing a blog post about plumbing and you say "a leak fix doesn't come much cheaper than a bottle of leak sealer at around 20 pounds," that's a factual claim with a number in it. Where did that number come from? If you don't link to a source, Google has no way to verify it.
This sounds trivial. It's not. These are the small things that separate content Google trusts from content it buries.
The rule of thumb: whenever you cite a statistic, a price, a percentage, or any factual claim, link it to the original source. Government websites, academic papers, and established industry publications carry the most weight.
For example, Ahrefs found that the pages most likely to be cited in AI Overviews consistently link out to authoritative sources. And according to Semrush, AI-referred website sessions grew by 527% between January and May 2025. That's the kind of traffic you're leaving on the table if your content can't be verified.
This also ties directly into AI content writing best practices. If you're using AI tools to draft content, make sure you're manually adding real, verifiable source links before publishing.
What Is Information Gain and Why Is It the Biggest Winner?
Information gain means adding something new to the conversation that the other top-ranking pages don't already say. According to Glenn Gabe, an SEO consultant at Search Engine Land, this is the single most consistent winner-and-loser signal from the entire March update.
If you do it, you win. If you don't, you lose.
Here's where most people go wrong: they look at the top 10 results for a keyword, rewrite essentially the same information in different words, and hit publish. That used to work. It doesn't anymore.
What works instead:
- Proprietary data: Share numbers from your own business, campaigns, or clients
- First-hand experience: Write about what you actually did, not what a textbook says
- A different angle: Challenge the consensus or cover a subtopic nobody else mentions
- Expert commentary: Interview someone with real credentials in the space
And here's what definitely does NOT work: making your post longer. If the top result is 1,500 words and you write 3,000, Google doesn't reward that. They actually consider it worse if the extra content is filler. Stop thinking about word count. Think about content quality.
A practical trick: Take the top-ranking blog posts for your target keyword, paste them into ChatGPT, Claude, or Google NotebookLM, and ask: "Is there a point that all these posts forget to mention about this topic?" Use that gap as your unique angle.
This is closely related to the capsule content method, which structures content so AI engines can easily extract and cite your unique insights. 72% of pages cited by ChatGPT use an "answer capsule" format. That's not a coincidence.
Do You Actually Need Schema Markup on Blog Posts?
Yes. Schema markup is a small piece of code in your page's header that tells search engines exactly what your content is about. Think of it as a nutrition label for your blog post.
Remember the author bio from earlier? There's an author schema that should go alongside it. This tells Google (in a machine-readable format) who wrote the piece, their credentials, and their social profiles.
Common schema types for blog posts:
- Article schema: Basic metadata (headline, date published, author)
- Author schema: Who wrote it and their credentials
- FAQPage schema: For FAQ sections (pages with this get 3.2x higher citation probability in AI search results)
- HowTo schema: For step-by-step guides
- Organization schema: For your brand's credibility signals
If you don't know which schema to add, don't worry. The audit tool I'll mention below tells you exactly which schema your specific blog post needs.
Schema isn't glamorous, but it gives you a measurable edge. Brands publishing structured data alongside their content see 45% more citations from AI search engines. When AI search visitors convert at 4.4x the rate of traditional organic visitors, that's real revenue you're leaving behind.
How Do You Add Original Data When You Don't Have Any?
This is the hardest trust signal to add, and that's exactly why it's so valuable. Google's quality raters and large language models can spot original data, and they reward it heavily.
Original data means screenshots, proprietary metrics, case studies, test results, or survey data that only you can provide. It's hard to fake because it requires you to actually do the work.
The easiest starting point: real case studies.
You don't need to run a formal study. Document the results of something you actually did. Show before-and-after screenshots. Share the numbers.
Community win: Sarah M., an agency owner in the AI Ranking community, started adding original client data and screenshots to her blog posts. Within three weeks, ChatGPT was citing her content directly. Her AI traffic went up 200%. Tim Armstrong, another member, had a client get a mortgage lead directly from a ChatGPT recommendation, all because the blog post included verifiable, original case study data.
If you truly have nothing original yet, here's how to start:
- Run a small experiment and document the results
- Survey your audience or clients and publish the findings
- Take screenshots of your own analytics, tools, or dashboards
- Share specific numbers from your own projects (even small ones count)
The point is to give Google something it can't find on any other website. That's the definition of information gain backed by data.
How Can You Audit All 5 Signals Quickly?
Use DataWise, the SEO application built by AI Ranking. It audits your blog posts for all five trust signals and tells you exactly what's missing and what to fix.
Fixing five different trust signals across dozens of old blog posts sounds overwhelming. DataWise makes it manageable by scanning your content, flagging the gaps, and recommending specific schema types, source opportunities, and author bio improvements.
You can try it free for 48 hours with the promo code KEYWORD48.
If you want to go deeper on how to get found in AI search and understand the full picture of AI search optimization, start with the audit. Then prioritize fixes based on which posts are already getting some traffic (those have the most to gain from trust signal improvements).
Frequently Asked Questions
How long does it take to see results after adding these trust signals?
It depends on your site's crawl frequency, but most sites see movement within one to three Google crawl cycles (roughly two to six weeks). Pages that already have some authority tend to respond faster. AI search engines like ChatGPT and Perplexity may pick up changes even sooner since they re-crawl frequently.
Does this update affect new blog posts or just old ones?
Both. Old blog posts without trust signals are getting demoted, but new posts published without them won't rank well either. The difference is that your old posts may have been ranking fine before this update and are now losing positions. New posts simply won't gain traction without these signals from the start. If you're using a Claude SEO assistant to write content, make sure it includes all five signals in every draft.
Which trust signal should I fix first?
Author bios and source links. They're the fastest to implement and have the most immediate impact. You can add an author bio to every post in an afternoon, and source links can be added as you review each post. Schema is next (especially FAQPage schema, which gives you that 3.2x citation boost). Information gain and original data take more effort but deliver the biggest long-term advantage.
Ready to Fix Your Blog Posts Before Google Drops Them?
This update isn't subtle. Google is actively rewarding content with verifiable trust signals and demoting content without them. The five signals (author bios, source links, information gain, schema markup, and original data) are your blueprint for staying visible in both traditional and AI search.
Here's what to do next:
- Audit your content with DataWise (free 48 hours, promo code KEYWORD48)
- Join the AI Ranking community at airankingskool.com for weekly tutorials, SEO reviews, and access to all our tools
- Watch the full video breakdown on YouTube: Google's March Update Is Killing Old Blog Posts (5 Fixes)
If you want to understand does Google penalize AI content or learn the full playbook for ranking in AI search engines, those guides pair perfectly with what you just learned here.
Resources
- Search Engine Land: Google March 2026 Core Update Rollout Complete
- SISTRIX: March 2026 Core Update Visibility Analysis
- Search Engine Roundtable: March 2026 Core Update Coverage
- Ahrefs: AI Overview Citations & Top 10 Analysis
- Semrush: AI Search SEO Traffic Study
- Seer Interactive: How Traffic from ChatGPT Converts
- Microsoft: Optimizing Content for AI Search Answers
- Dataslayer: Google AI Overviews & CTR Impact
- DataWise SEO Tool (free 48-hour trial with code KEYWORD48)
- AI Ranking Community
Google's March 2026 Core Update: 5 Trust Signals Your Blog Posts Need Right Now
Stay Updated with Our Insights
Subscribe to our newsletter for the latest tips and trends in AI-powered SEO.